Deploying Next.js on Cloudflare Workers with Terraform-First Approach

At AirHelp, our classic approach to deploying web applications is battle-tested: we build a Docker image and deploy it to our infrastructure on AWS EKS. For most of our applications, this model is reliable and robust.
However, this approach presents a significant challenge for our main website, airhelp.com: deployment time. A standard deployment takes roughly 20 minutes to complete. When a critical hotfix is needed, the process of deploying to a staging environment and then promoting to production can extend this to nearly 30 minutes. If a bug slips past our caching layer, a simple mistake could translate into a 30-minute outage.
Beyond deployment speed, our traditional architecture introduces inherent latency for our global user base. Serving content from a centralized region is no longer enough to meet the performance expectations of a modern web application, and we began to notice the impact.
The question became clear: Can we do this simpler, faster, and more performant?
Finding the Right Path
I've been watching Cloudflare's solutions evolve for the past couple of years, and they always seemed promising for smaller projects. However, our main website at AirHelp is far from a simple static page that you can deploy to Cloudflare Pages and forget about.
A key challenge for us is ensuring a smooth integration with our headless CMS, allowing content editors to publish and update content effortlessly. Triggering a full new deployment for every content change is not an option. Furthermore, those changes must be reflected on the live site almost instantly. The clear solution to this is Next.js's Incremental Static Regeneration (ISR) feature.
This requirement led us directly to Cloudflare Workers. While Pages are excellent for static sites, Workers provide the powerful, flexible serverless runtime needed to handle dynamic, on-demand functions like ISR. It gives us the raw compute at the edge to build a truly modern, high-performance web application.
Our Non-Negotiable Requirements
To make this vision a reality, we first needed to find a way to run a full-featured Next.js application on the Workers runtime. Then, we had to ensure the solution could meet our organization's strict engineering standards.
A critical component of this project is OpenNext, an open-source adapter that makes it possible to run standard Next.js applications on various serverless platforms, including Cloudflare Workers. It's a community-driven project, with the Cloudflare adapter being actively maintained by the Cloudflare team. The adapter works by taking the standard next build output and transforming it into a format compatible with the Cloudflare Workers runtime.
With the right tool identified, we defined three non-negotiable principles for the project:
- Infrastructure as Code is the Single Source of Truth. We use a centralized Terraform repository to manage our Cloudflare resources. This approach is fundamental as it minimizes the need for direct developer access to the Cloudflare Dashboard and gives us complete control and auditability.
- Deployment Pipelines Cannot Create Infrastructure. The
wrangler.toml- the configuration manifest for a Worker - is a powerful tool, but we needed to restrict its ability to create resources on the fly. This is a crucial safeguard to prevent deployments to the default*.workers.devsubdomain, ensuring all public routes are managed exclusively by Terraform. - Automation via Reusable CI/CD Workflows. The entire deployment process must be automated using robust, reusable GitHub Actions that can reliably build the application, package it for Cloudflare, and deploy the new version.
Managing Infrastructure as Code
The cornerstone of our entire solution is managing the worker and its resources strictly through Terraform. In a typical Cloudflare project, the wrangler.toml is often responsible for creating resources like the script itself, routes, R2 buckets, and service bindings. This is convenient for small projects but incompatible with enterprise governance.
We wanted to avoid this at all costs. Our solution enforces strict separation:
- Terraform - creates and owns all infrastructure (workers, routes, R2 buckets, bindings)
- CI/CD - can ONLY update the worker script content, nothing else
The magic happens through name matching: the name field in wrangler.toml must exactly match the worker_script_name defined in our Terraform module. As long as the names, Account ID, and Zone ID align, Wrangler can successfully deploy new code to the infrastructure provisioned by Terraform.
Understanding the Required Resources for Next.js App
To run a Next.js application with fully functional ISR, we determined that our Terraform module needed to provision three core resources beyond the worker script itself:
- A Public R2 Bucket for Static Assets. This bucket stores the application's public assets (CSS, JavaScript, images) and serves them directly to users. It must be publicly accessible via a Cloudflare-managed domain.
- A Private R2 Bucket for ISR Cache. This bucket stores the cached pages and data for ISR. It remains private, as it's only ever accessed by the Worker itself. It must be named
NEXT_INC_CACHE_R2_BUCKET(OpenNext requirement) - A Service Binding for Self-Reference. This allows the Worker to call itself internally to trigger background cache revalidation tasks without making a public HTTP request.
Why a Dedicated, Public R2 Bucket for Assets?
OpenNext's built-in assets binding creates resources automatically at deployment time. This creates a conflict with Terraform, which sees this "magical," unmanaged resource as state drift and will try to remove it on the next apply. This leads to a constant battle between our deployment tool (Wrangler) and our infrastructure manager (Terraform).
Our explicit R2 bucket approach maintains single source of truth: Terraform owns infrastructure, CI/CD fills it with content.
Terraform Module in Action
With these requirements in mind, we built a flexible module that provisions a worker with a simple "Hello World" script. This acts as a placeholder for the infrastructure, which is later updated by our CI/CD pipeline.
The core of the module is the cloudflare_workers_script resource, which dynamically configures all the necessary bindings based on input variables.
# Core routing configuration
resource "cloudflare_workers_route" "this" {
for_each = var.enable_route ? toset(var.domains) : toset([])
zone_id = module.zone_ids.domains[each.value]
pattern = "${join(".", compact([var.subdomain, each.value]))}/${var.path_pattern}"
script = cloudflare_workers_script.this.script_name
}
# Private bucket for ISR cache
resource "cloudflare_r2_bucket" "data_bucket" {
count = var.enable_r2_data ? 1 : 0
account_id = var.account_id
name = "${replace(var.worker_script_name, "_", "-")}-data" # Underscores not allowed
}
# Public bucket for static assets
resource "cloudflare_r2_bucket" "assets_bucket" {
count = var.enable_r2_assets ? 1 : 0
account_id = var.account_id
name = "${replace(var.worker_script_name, "_", "-")}-assets"
}
# Makes assets bucket publicly accessible
resource "cloudflare_r2_managed_domain" "assets_bucket_managed_domain" {
account_id = var.account_id
bucket_name = cloudflare_r2_bucket.assets_bucket[0].name
enabled = true
}
# The worker itself with all bindings
resource "cloudflare_workers_script" "this" {
account_id = var.account_id
script_name = var.worker_script_name
# Placeholder content - will be replaced by CI/CD
content = <<-EOT
addEventListener('fetch', event => {
event.respondWith(new Response('Hello from Terraform!'))
})
EOT
# Dynamic bindings based on configuration
bindings = concat(
# ISR cache bucket
var.enable_r2_data ? [{
name = var.r2_data_binding_name # Can override to "NEXT_INC_CACHE_R2_BUCKET"
type = "r2_bucket"
bucket_name = cloudflare_r2_bucket.data_bucket[0].name
service = null
}] : [],
# Static assets bucket
var.enable_r2_assets ? [{
name = var.r2_assets_binding_name # Default: "ASSETS"
type = "r2_bucket"
bucket_name = cloudflare_r2_bucket.assets_bucket[0].name
service = null
}] : [],
# Self-reference for ISR
var.enable_self_binding ? [{
name = var.self_binding_name # Default: "WORKER_SELF_REFERENCE"
type = "service"
service = var.worker_script_name
bucket_name = null
}] : []
)
# Critical: prevents Terraform from reverting code
lifecycle {
ignore_changes = [
content,
content_file,
compatibility_date,
]
}
The most critical part of this resource is the lifecycle block. The ignore_changes directive is the magic that makes our entire workflow possible. It tells Terraform:
"You are responsible for everything except the script's content. Never touch it."
This prevents Terraform from reverting our application code back to "Hello World" on the next apply.
It's important to understand a key limitation of this approach. While ignore_changes prevents Terraform from reverting the script on a typical terraform plan when only the live code has changed, it does not protect the script content if you modify another argument within the same cloudflare_workers_script resource in your code.
For instance, if you add a new R2 binding in your Terraform file and run terraform apply, Terraform needs to update the entire resource. During this update, it will use the content defined in your .tf file (the "Hello World" placeholder), overwriting the application code deployed by your CI/CD pipeline.
This means that after making any Terraform changes to the worker resource itself, you must immediately re-run your CI/CD deployment pipeline to restore the correct application code.
Using the Module
Using the module to provision the entire infrastructure for a new Next.js application is now straightforward.
module "simple_worker_example" {
source = "<module-path>/cloudflare/workers"
account_id = "<account-id>"
application = "simple-app"
subdomain = "simple-worker"
domains = ["airhelp.dev"]
worker_script_name = "example_worker"
enable_route = true
enable_r2_data = true
enable_self_binding = true
enable_r2_assets = true
r2_data_binding_name = "NEXT_INC_CACHE_R2_BUCKET"
}
As a result, in the Cloudflare dashboard we can see the created example_worker with the 3 bindings that we set in our module
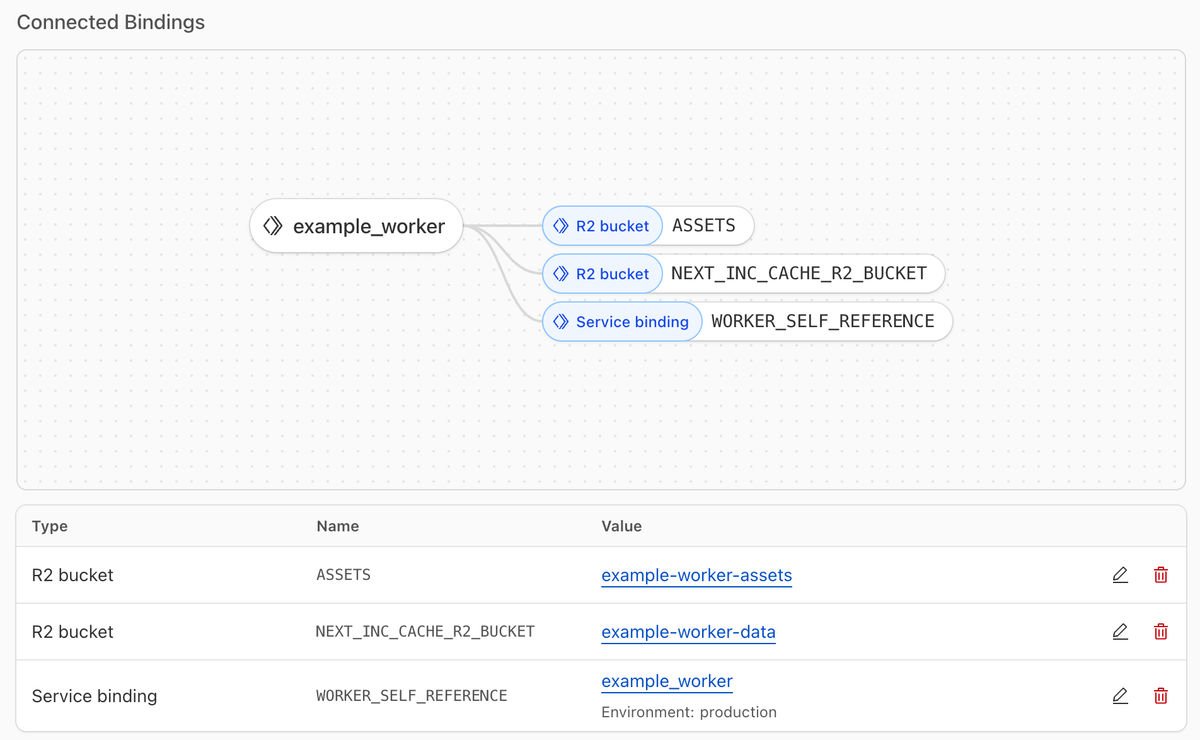
Bridging Terraform and the Application
With the infrastructure provisioned by Terraform, the final step is to ensure our deployment pipeline knows how to connect the application code to these resources. This is handled by the wrangler.toml file, a manifest that instructs the Wrangler CLI on what to deploy and how to bind it.
An example wrangler.toml for our application looks like this:
name = "example_worker"
main = ".open-next/worker.js"
compatibility_date = "2025-03-01"
compatibility_flags = [
"nodejs_compat",
"global_fetch_strictly_public",
]
[[r2_buckets]]
binding = "ASSETS"
bucket_name = "example-worker-assets"
[[r2_buckets]]
binding = "NEXT_INC_CACHE_R2_BUCKET"
bucket_name = "example-worker-data"
[[services]]
binding = "WORKER_SELF_REFERENCE"
service = "example_worker"
The critical principle here is name consistency, which enforces our IaC-first policy.
- The top-level
name(example_worker) must exactly match theworker_script_namefrom our Terraform module. This is the key that tells Wrangler which existing script to update. - The
bucket_namevalues (e.g.,example-worker-assets) must match the names of the R2 buckets that Terraform created. - The
servicein theWORKER_SELF_REFERENCEbinding must match the worker's own name, creating the internal loopback required for ISR.
If any of these don't match, you'll get deployment errors. The worker won't find its buckets, ISR won't work, or worse - Wrangler might try to create new resources, breaking our IaC principle.
This approach is also a necessary safeguard due to a current limitation in Cloudflare’s permissions. The required Workers Script | Edit permission is broad enough to allow changes to a worker's bindings, not just its code. Our custom CI/CD validation is therefore essential to truly enforce our IaC-first policy, bridging a gap in the platform's native RBAC.
This configuration deliberately excludes:
- No route definitions (managed by Terraform)
- No
workers_dev = true(we'll enforce false in CI/CD) - No account or zone IDs (inherited from environment)
This setup ensures a clean separation of concerns: developers only need to ensure names match. They can't accidentally modify infrastructure, create public endpoints, or bypass our governance.
Automating Deployments with GitHub Actions
The next step was to automate our deployments and bridge the gap between our Terraform-managed infrastructure and the application code. A standard approach might involve using the official cloudflare/wrangler-action, but our use case with OpenNext required a more tailored solution. The OpenNext adapter uses its own distinct commands for building and deploying (opennextjs-cloudflare build and opennextjs-cloudflare deploy).
Furthermore, we needed to inject static assets into our public R2 bucket and enforce our strict IaC validation rules. This led us to develop a custom, reusable GitHub Actions workflow.
Our workflow consists of several key stages:
Steps 1 & 2: Pre-Deployment Validation
Before any code is built, the workflow performs two critical validation checks to enforce our "Terraform-first" philosophy.
- Validate
wrangler.toml: The first step verifies that thewrangler.tomlmanifest file exists. It then ensures the settingworkers_dev = falseis present, which prevents the pipeline from creating a public*.workers.devURL and guarantees that Terraform remains the sole manager of public routes. - Verify Worker Exists: The second check queries the Cloudflare API to confirm that the worker script, as named in
wrangler.toml, already exists in our account. This ensures we only deploy code to resources that have been properly provisioned and tracked by Terraform.
Step 3: Building the Application with the Correct Asset Path
With validation passed, the workflow proceeds to install dependencies and build the Next.js application. A crucial part of this step is configuring the application to serve static assets from the correct location.
As the Next.js application is built, it needs to know the public URL of the R2 bucket that we provisioned with Terraform. We pass this URL into the build step via the NEXT_PUBLIC_ASSET_PREFIX environment variable. The value for this variable is sourced from our Terraform output and stored securely as a GitHub Actions variable or secret. This instructs Next.js to generate all static asset links pointing to our dedicated R2 storage.
const nextConfig: NextConfig = {
// ...
assetPrefix: process.env.NODE_ENV === "production" ? process.env.NEXT_PUBLIC_ASSET_PREFIX : undefined,
};
Step 4: Synchronizing Static Assets with R2
After the OpenNext build process completes, it places all static assets in a local .open-next/assets directory. The next step in our workflow is to upload the contents of this directory to our public R2 bucket. A custom script iterates through the directory and uses the wrangler r2 object put command to upload each file, effectively populating the empty bucket that Terraform created.
It is critical that this command is run with the --remote flag. Without it, Wrangler defaults to interacting with a local simulation of R2 storage, rather than the live bucket on Cloudflare’s network.
Step 5: Deploying the Worker Code
With the validation passed, the application built with the correct asset prefix, and the static files synchronized to R2, the final step is a single command: opennextjs-cloudflare deploy. This pushes the transformed worker code to Cloudflare, completing the deployment.
This multi-step process, codified in a single workflow, gives us the perfect balance of automation and control. Here is what the complete workflow looks like in practice:
name: Deploy Next.js application to Cloudflare Workers
on:
workflow_call:
inputs:
environment:
description: "Environment to deploy to"
type: string
default: sta
node-version:
type: string
description: Node.js version to use
required: false
default: 22.12.0
assets-bucket-name:
description: "The name of the R2 bucket for static assets"
required: true
type: string
assets-bucket-url:
description: "URL of the R2 assets bucket"
required: false
type: string
env:
BUILD_ENV: ${{ inputs.environment }}
jobs:
deploy-to-cloudflare:
name: Build and publish application to cloudflare
runs-on: [ubuntu-latest]
steps:
- name: Checkout code
uses: actions/checkout@v5
- name: Setup Node.js
uses: actions/setup-node@v5
with:
node-version: ${{ inputs.node-version }}
- name: Install pnpm
uses: pnpm/action-setup@v4
with:
version: 8
- name: Validate wrangler.toml
run: |
if [ ! -f wrangler.toml ]; then
echo "❌ Error: wrangler.toml not found!"
exit 1
fi
if ! grep -q "^workers_dev" wrangler.toml; then
echo "'workers_dev' setting not found. Prepending 'workers_dev = false' to wrangler.toml..."
# Prepend the setting to the first line of the file to ensure it's a top-level key.
# The '\n' adds a blank line after for better readability.
sed -i '1i workers_dev = false\n' wrangler.toml
echo "✅ wrangler.toml has been updated for this deployment."
else
echo "👍 'workers_dev' setting is already present."
fi
- name: Verify worker script exists in Cloudflare
run: |
WORKER_NAME=$(grep "^name =" wrangler.toml | awk -F '"' '{print $2}')
if [ -z "$WORKER_NAME" ]; then
echo "❌ Error: Could not read 'name' from wrangler.toml"
exit 1
fi
echo "Verifying that worker script '$WORKER_NAME' exists..."
HTTP_STATUS=$(curl -s -o /dev/null -w "%{http_code}" \
-X GET "https://api.cloudflare.com/client/v4/accounts/${{ vars.CLOUDFLARE_ACCOUNT_ID }}/workers/scripts/$WORKER_NAME" \
-H "Authorization: Bearer ${{ secrets.CLOUDFLARE_WORKERS_API_TOKEN }}" \
-H "Content-Type: application/json")
if [ "$HTTP_STATUS" -eq 200 ]; then
echo "Worker script found (HTTP 200). Proceeding with deployment."
else
echo "❌ Error: Worker script '$WORKER_NAME' not found (HTTP $HTTP_STATUS)."
echo "Please ensure it has been created with Terraform first."
exit 1
fi
- name: Install dependencies
run: pnpm install
- name: Build Next.js app with OpenNext
run: pnpm exec opennextjs-cloudflare build
env:
NODE_ENV: production
NEXT_PUBLIC_ASSET_PREFIX: ${{ inputs.assets-bucket-url }}
- name: Sync Static Assets to R2
env:
CLOUDFLARE_ACCOUNT_ID: ${{ vars.CLOUDFLARE_ACCOUNT_ID }}
CLOUDFLARE_API_TOKEN: ${{ secrets.CLOUDFLARE_WORKERS_API_TOKEN }}
BUCKET_NAME: ${{ inputs.assets-bucket-name }}
run: |
set -e
SOURCE_DIR=".open-next/assets"
if [ ! -d "$SOURCE_DIR" ]; then
echo "❌ Error: Directory $SOURCE_DIR not found. Did the build step run correctly?"
exit 1
fi
echo "Synchronizing $SOURCE_DIR with R2 bucket: $BUCKET_NAME"
find "$SOURCE_DIR" -type f | while read -r FULL_PATH; do
KEY="${FULL_PATH#"$SOURCE_DIR/"}"
echo " Uploading: $FULL_PATH as $KEY"
pnpm exec wrangler r2 object put "$BUCKET_NAME/$KEY" --file="$FULL_PATH" --remote
done
echo "✅ Asset synchronization complete."
- name: Deploy to Cloudflare Workers
run: pnpm exec opennextjs-cloudflare deploy
env:
CLOUDFLARE_ACCOUNT_ID: ${{ vars.CLOUDFLARE_ACCOUNT_ID }}
CLOUDFLARE_API_TOKEN: ${{ secrets.CLOUDFLARE_WORKERS_API_TOKEN }}
Our workflow successfully enabled the deployment of the application to the existing worker!

ISR in Action
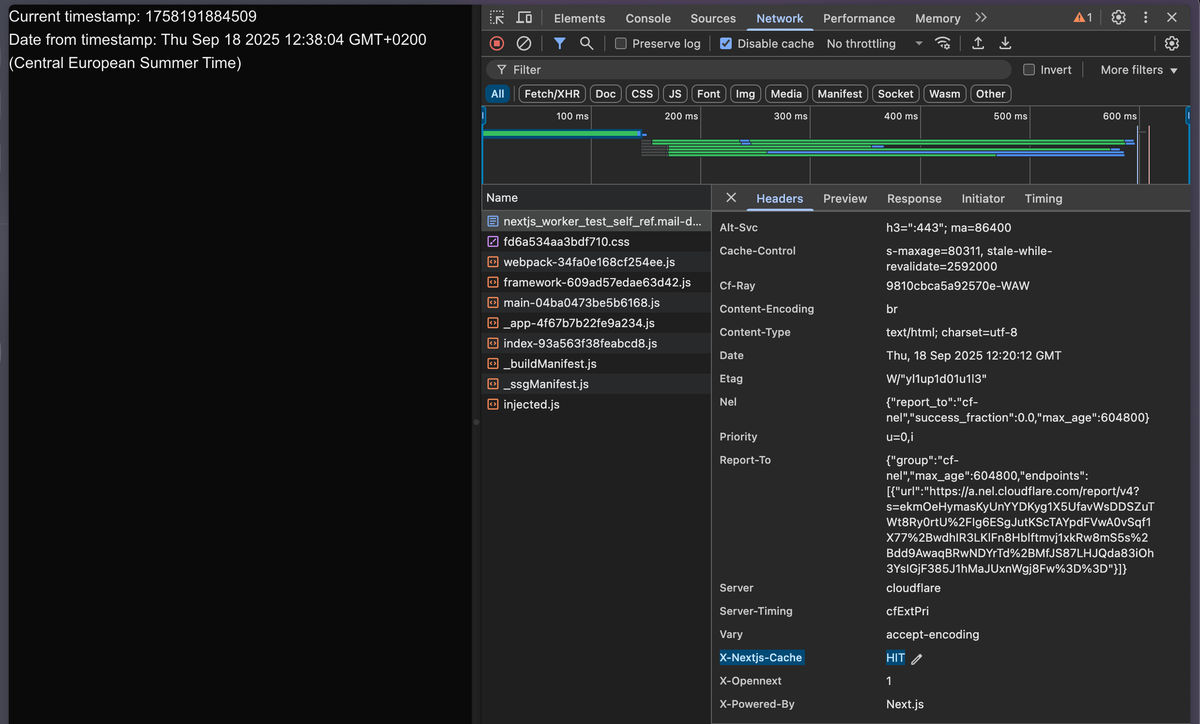
With the infrastructure provisioned and the deployment pipeline configured, the final step was to prove that it all works. We successfully deployed the Next.js application, and the most satisfying proof came directly from the browser's Network tab: the response for a pre-rendered page now includes the x-nextjs-cache: HIT header. This confirmed that content was being served directly from the Cloudflare cache instead of being server-rendered on every request.
This validated our entire setup, delivering a fully functional site with both time-based and on-demand ISR.
Time-Based Revalidation
To demonstrate the core ISR functionality, we created a simple homepage using the Pages Router. The page displays a timestamp that is generated at build time.
// pages/index.tsx
export default function Home({ timestamp }: { timestamp: number }) {
const dateFromTimestamp = new Date(timestamp);
return (
<div>
<p>Current timestamp: {timestamp}</p>
<p>Date from timestamp: {dateFromTimestamp.toString()}</p>
</div>
);
}
export async function getStaticProps() {
return {
props: {
timestamp: Date.now(),
},
// ISR revalidate every 24 hours (will be overridden by on-demand webhook)
revalidate: 86400,
};
}
The key here is the revalidate: 86400 property. This tells Next.js to serve the statically generated page from the cache, and after 24 hours, the next request will trigger a revalidation in the background. The user gets a fast, cached response, while the content is kept fresh.
On-Demand Revalidation via Webhook
Waiting for a timer isn't enough for a modern CMS. So, we need to update content the moment an editor hits "publish." To achieve this, we created a simple on-demand revalidation API endpoint. This endpoint, which would be secured and triggered by a webhook from our CMS, allows us to instantly purge and regenerate specific pages.
// pages/api/revalidate.ts
import { NextApiRequest, NextApiResponse } from "next";
export default async function handler(
req: NextApiRequest,
res: NextApiResponse
) {
// For a real-world app, add security checks here (e.g., a secret token)
if (req.method !== "POST") {
return res.status(405).json({ message: "Method not allowed" });
}
try {
const path = req.body.path;
if (!path) {
return res.status(400).json({ message: "Missing path in payload" });
}
await res.revalidate(path);
return res.status(200).json({ revalidated: true, path });
} catch (err) {
return res.status(500).json({ message: "Error revalidating" });
}
}
To test this endpoint, we can send a simple curl request:
curl -X POST https://simple-worker.airhelp.dev/api/revalidate \
-H "Content-Type: application/json" \
-d '{"path":"/"}'
Why did this work? This simple command proves that our entire architecture is functioning in harmony. The request hits the Cloudflare network and is routed to our Worker. The OpenNext adapter correctly forwards the API call to the Next.js handler. The handler then uses Next.js's built-in res.revalidate() function, which (under the hood) leverages the WORKER_SELF_REFERENCE and NEXT_INC_CACHE_R2_BUCKET bindings we configured in Terraform to purge the stale content from the R2 cache.
The next user visiting the homepage gets a freshly rendered version with a new timestamp. Subsequent visitors are served this new, cached version, confirmed by the x-nextjs-cache: HIT header in the browser's network tab. This is the full ISR loop in action, powered entirely by our IaC-defined serverless infrastructure.
Initial Findings and Future Challenges
While this project was a Proof-of-Concept, it provided invaluable insights into the benefits of moving our Next.js applications to a serverless architecture on Cloudflare.
A Simpler, Faster Future
The most immediate win was the simplified deployment process. We anticipate our deployment times will drop from over 20 minutes to less than 5, replacing a complex Docker-based workflow with a direct deployment to the edge. We also expect a significant performance boost for our global users. Serving content and assets directly from Cloudflare's network is a clear path to reducing latency and improving our Core Web Vitals.
Lessons Learned
Our strict "Terraform-first" approach created a fascinating challenge: how do you prevent Terraform from reverting application code deployed by a separate CI/CD pipeline? We discovered that a terraform apply modifying a worker's configuration would overwrite the live code with the "Hello World" placeholder from our module.
The solution was the lifecycle block within our cloudflare_workers_script resource. By adding ignore_changes = [content], we explicitly told Terraform that it is responsible for every aspect of the worker except for the application code itself. This created a clean and robust separation of concerns, allowing our infrastructure and deployment tools to work in harmony.
However, this solution has a critical caveat: changing other resource arguments (like a new binding) will cause Terraform to revert the script content. While our current workaround is an immediate CI/CD re-run, we recognize this manual step is a risk for production. Our goal is to fully automate this recovery step, for instance by having the Terraform pipeline trigger the application deployment, before this pattern is used in a live environment.
From Proof of Concept to Production
While this PoC was a resounding success, several key challenges must be addressed before this can move to production. The next steps on our journey are:
- Communication with AWS-based Services: A significant challenge is establishing secure communication with our existing services hosted on AWS. The likely path involves using a Cloudflare Tunnel for a secure, private connection back to our VPC, allowing the Worker to interact with applications running in our internal domains.
- Secrets Management: We plan to integrate Cloudflare's encrypted secrets into our deployment pipeline. This will involve enhancing our GitHub Actions workflow to use the
wrangler secret putcommand, securely transmitting secrets directly to the Worker's runtime environment. - Observability and Grafana Integration: A production application requires robust monitoring. The next phase will involve leveraging Cloudflare's built-in observability tools and forwarding logs and metrics to our central Grafana stack.
Our journey from a traditional Docker setup to a modern serverless stack on Cloudflare has been a resounding success. This Proof-of-Concept proved that we can build a faster, simpler, and more performant frontend architecture without sacrificing our core engineering principles of control and automation.
We're excited by these results and look forward to building on this foundation to redefine how we deliver web applications at AirHelp.

Dominik Woźniak
Software Engineer