Git data model - Deep dive for Software Engineers

Mastering the Git client is just the beginning. Dive into the elegance and simplicity of Git's data structures.
In this article, you'll learn how to set up a functional repository by building files from scratch inside the .git directory! This guide is tailored for those who are well-acquainted with Git and aim to optimize their daily workflows.
It will not only enhance your understanding of the tool but also elevate your data-design engineering skills.
Discover how simple structures can yield immense functionality.
History
In today's tech landscape, it's hard to imagine a world without Git. Linus Torvalds, faced with the inefficiencies of existing tools, adopted a principle: if it doesn't exist, create it.
The core principle behind Git was to establish a distributed system in the first place. This ensures that any modifications to data don't go unnoticed. With a single hash, you can be certain of the integrity of all your files. As a result, it becomes impossible for anyone, even government officials, to introduce falsified data without it being instantly detected by the community.
Given its distributed nature, data is designed to fit into every client device. Therefore, every collaborator has the entire repository. This design makes Git both fast and reliable. You have the capability to work offline, secure in the knowledge that all data is accessible, even without internet access.
Structure
Let's take a look at Git architecture. Instead of depending on a conventional file system, Git employs its own unique abstraction, enabling its internals to focus less on the fact that they operate with files.
Git interprets the file system distinctively:
- A file translates to a blob.
- A folder is a tree of blobs.
- The state of a file system is represented by a commit.
Whenever you reference a name referring to a tag or branch, there's an underlying hash. Additionally, Git employs hashes to identify every object within its system. This efficiency in using hashes over files is a key reason for Git's speed. It's worth noting that commit objects don't store diffs. Rather, each commit object contains a hash to the tree, which recursively and completely defines the content of the source tree at that commit.
The data adheres to the principles of DAG (Directed Acyclic Graph) and the Merkle Tree, sometimes referred to as the Merkle DAG. This ensures that if any corruption occurs, the hashes will differ, allowing Git to detect the discrepancy.
Consequently, it provides security against source code attacks (that fits within a lifetime).
Start
To get started, first create a new directory for our project.
$ mkdir my-project
$ cd my-project
If you run git status, you'll encounter an error stating that this isn't a git repository.
$ git status
fatal: not a git repository (or any of the parent directories): .git
So, let's initiate one. We'll set up local configuration files for git. We need to create the directories objects and refs. The objects directory will store all the objects in the repository, while the refs directory will hold pointers to commits.
$ mkdir .git
$ mkdir .git/objects
$ mkdir .git/refs
However, that's still not enough. We'll create a file that tells Git where we are in the commit history. This file is named HEAD, which serves as a reference to the commit or branch we're currently on. Let's establish a branch named main and set HEAD to point to it.
$ echo "ref: refs/heads/main" > .git/HEAD
Great! Now, when you run `git status``, it will proceed without any errors and inform you that the repository is empty.
$ git status
On branch main
No commits yet
nothing to commit (create/copy files and use "git add" to track)
First file
Every modern repo should have a README. Let's create one.
$ echo "Hello, AirHelp world\!" > README.md
$ git status
On branch main
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
README.md
nothing added to commit but untracked files present (use "git add" to track)
Status message has changed, but this information is generated only by the client. If we inspect the .git directory, we'll see that nothing has changed there.
$ tree .git
.git
├── HEAD
├── objects
└── refs
We'll change that now by adding the file to the staging area. But, instead of using the git add README.md command, we'll do it manually.
We already know that everything Git stores is treated as an object. Objects that store a file are of the blob type. Our goal is to create a blob object for our README.md file. A blob's format is straightforward:
blob [content-length]\0[content]
This signifies that only the content of the file matters, not attributes like the path or filename. Each change is stored as a new object. Git stores the entire file content, not just the changes.
The content is then hashed using sha1.
$ printf "blob 22\0Hello, AirHelp world\!\n" | shasum
f213327331d92d4f91c2963cbb7c037eb3849555 -
This hash will help us create a path name for the file. Git objects are stored in the .git/objects directory. The first two characters of the hash serve as directory name, while the rest become the filename.
$ mkdir .git/objects/f2
$ printf "blob 22\0Hello, AirHelp world\!\n" > .git/objects/f2/13327331d92d4f91c2963cbb7c037eb3849555
Now, our file is recognized by Git.
$ git status
On branch main
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: README.md
If we attempt to view the file content using the git command, it's unreadable.
$ git cat-file -p f213327331d92d4f91c2963cbb7c037eb3849555
error: inflate: data stream error (incorrect header check)
error: unable to unpack f213327331d92d4f91c2963cbb7c037eb3849555 header
fatal: Not a valid object name f213327331d92d4f91c2963cbb7c037eb3849555
That is because Git doesn't store objects in plain text. Each file has to be compressed using zlib. We can create aliases to handle compression easily.
alias zlib-compress="ruby -r zlib -e 'print Zlib::Deflate.deflate(ARGF.read)'"
alias zlib-decompress="ruby -r zlib -e 'print Zlib::Inflate.inflate(ARGF.read)'"
Let's compress our file:
printf "blob 22\0Hello, AirHelp world\!\n" | zlib-compress > .git/objects/f2/13327331d92d4f91c2963cbb7c037eb3849555
Now, the file aligns with Git standard storage format. Using git cat-file, we can inspect any hash, viewing its content and type:
$ git cat-file -t f213327331d92d4f91c2963cbb7c037eb3849555
blob
$ git cat-file -p f213327331d92d4f91c2963cbb7c037eb3849555
Hello, AirHelp world!
$ git status
...
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: README.md
Here is the current state of the .git directory.
$ tree -C .git
.git
├── HEAD
├── index
├── objects
│ └── f2
│ └── 13327331d92d4f91c2963cbb7c037eb3849555
└── refs
Root directory
Now that we have our file correctly added, we need to add a folder that serves as the root of our repo. In Git, every folder is represented by a tree object. Once the tree is created, we will be able to create a commit.
Tree object format:
tree [content size]\0[entries]
Each entry, which can reference other trees or blobs, follows the format:
[mode] [name]\0[SHA-1 of referenced blob or tree]
The SHA-1 is a hash of the object in binary form. The "mode" represents the file mode, for instance, 100644 for a regular file and 40000 for a directory. This file mode is similar to the one used by the Unix chmod command.
To generate that object, we will use an interactive Ruby console. It will allow us to see how data is assembled. To enter the console:
$ irb -r zlib -r digest/sha1
In the console, let's first create the variables.
irb> blob_content = "blob 22\0Hello, AirHelp world!\n"
# "blob 22\u0000Hello, AirHelp world!\n"
irb> blob_digest = Digest::SHA1.digest(blob_content)
# "\xF2\x132s1\xD9-O\x91\xC2\x96<\xBB|\x03~\xB3\x84\x95U"
irb> file_name = "README.md"
# "README.md"
irb> mode = "100644"
# "100644"
irb> content = "#{mode} #{file_name}\0#{blob_digest}"
# "100644 README.md\x00\xF2\x132s1\xD9-O\x91\xC2\x96<\xBB|\x03~\xB3\x84\x95U"
irb> content_length = content.length
# 37
irb> tree = "tree #{content_length}\0#{content}"
# "tree 37\x00100644 README.md\x00\xF2\x132s1\xD9-O\x91\xC2\x96<\xBB|\x03~\xB3\x84\x95U"
irb> tree_sha = Digest::SHA1.hexdigest(tree)
# "f17c8d019eac8b1b4f765a4e9425304d8e318db3"
irb> tree_zlib = Zlib::Deflate.deflate(tree)
# "x\x9C+..."
With the file compressed, we need to save it, following the same path pattern as for the blob:
irb> FileUtils.mkdir_p(".git/objects/f1/")
# [".git/objects/f1/"]
irb> File.write(".git/objects/f1/7c8d019eac8b1b4f765a4e9425304d8e318db3", tree_zlib)
# 54
With this, our tree object is created.
$ git cat-file -t f17c
tree
$ git cat-file -p f17c
100644 blob f213327331d92d4f91c2963cbb7c037eb3849555 README.md
Commit
Now, it's a commit time! 🥳
The commit object has a simple format:
commit [size]\0[content]
Where the content format is:
tree [tree hex sha]
[parents if any]
author [user identification] [date]
committer [user identification] [date]
[commit message]
User identification consists of: [author name] <[author email]>. A commit usually has one parent. In the case of a merge, it can have multiple parents, where each parent is listed on a new line with the format parent [parent hex sha]. As in this case, if it's the first commit, the parent line is omitted.
So, let's build our first commit object. We'll use the same approach as before.
# prepare commit
tree_sha = "f17c8d019eac8b1b4f765a4e9425304d8e318db3"
author = "Uncle Joe <[email protected]>"
date = "1356994800 +0000"
message = "Create README.md"
content = "tree #{tree_sha}\nauthor #{author} #{date}\ncommitter #{author} #{date}\n\n#{message}\n"
commit = "commit #{content.size}\0#{content}"
# hash it
commit_sha = Digest::SHA1.hexdigest(commit)
commit_zlib = Zlib::Deflate.deflate(commit)
# save it
FileUtils.mkdir_p(".git/objects/#{commit_sha[0..1]}/")
File.write(".git/objects/#{commit_sha[0..1]}/#{commit_sha[2..]}", commit_zlib)
This generated us a commit with the hash cd25c7d055e81836f43412ac8d5811d35319305a and the content in plaintext:
commit 169\0tree f17c8d019eac8b1b4f765a4e9425304d8e318db3
author Uncle Joe <[email protected]> 1356994800 +0000
commiter Uncle Joe <[email protected]> 1356994800 +0000
Create README.md
Let's see what it looks like using plumbing commands:
$ git cat-file -t cd25c7d055e81836f43412ac8d5811d35319305a
commit
$ git cat-file -p cd25c7d055e81836f43412ac8d5811d35319305a
tree f17c8d019eac8b1b4f765a4e9425304d8e318db3
author Uncle Joe <[email protected]> 1356994800 +0000
commiter Uncle Joe <[email protected]> 1356994800 +0000
Create README.md
As this file is commited, we must change our branch to see changes. File that says to git on which branch you are (.git/HEAD) is already set. Now, point a main branch to our commit:
mkdir -p .git/refs/heads
echo "cd25c7d055e81836f43412ac8d5811d35319305a" > .git/refs/heads/main
Great! Almost done. There is only one thing that is left to do - update index cache. This is an internal client binary format, which we won't cover. You can read more about it here. We can use the git update-index --add README.md command to do that. You can also checkout to our branch git checkout -f main. Whatever you choose, you can see that you are on clean branch:
$ git status
On branch main
nothing to commit, working tree clean
Current structure of the .git directory contains our commit.
$ tree -C .git
.git
├── HEAD
├── index
├── objects
│ ├── cd
│ │ └── 25c7d055e81836f43412ac8d5811d35319305a
│ ├── f1
│ │ └── 7c8d019eac8b1b4f765a4e9425304d8e318db3
│ └── f2
│ └── 13327331d92d4f91c2963cbb7c037eb3849555
└── refs
└── heads
└── main
Git logs display our commit.
$ git log
commit cd25c7d055e81836f43412ac8d5811d35319305a
Author: Uncle Joe <[email protected]>
Date: Mon Dec 31 23:00:00 2012 +0000
Create README.md
Congratulations! You've just created your first commit from scratch. 🎉
Second commit
Remember that every time you commit a file, Git automatically executes the steps you've just performed.
Additionally, Git contains "plumbing commands", which are part of its internal API. We'll use these to craft our second commit. Now, things have become simpler. Let's create a second file:
$ echo "git is fun" > second_file.txt
We can use a plumbing command to create a blob.
$ git hash-object -w second_file.txt
a4a10fd93d3b469fd68bbe63e14feefb33db101a
$ git cat-file -p a4a10fd93d3b469fd68bbe63e14feefb33db101a
git is fun
To create a blob and update the index cache, you can use the git update-index --add second_file.txt command.
To do that in daily operations, we often use an alternative, a more user-friendly commands known as "porcelain" commands:
$ git add .
$ git show a4a10fd93d3b469fd68bbe63e14feefb33db101a
git is fun
Now, you'll notice that our file is listed in the .git/index as a staged file:
$ git ls-files --stage
100644 f213327331d92d4f91c2963cbb7c037eb3849555 0 README.md
100644 a4a10fd93d3b469fd68bbe63e14feefb33db101a 0 second_file.txt
Next, let's create a tree object for our second commit. Observe that the tree object contains two blobs, identical to our directory:
$ git write-tree
384ec8c5f167e99bb47dfd3bbff7f5d23877c8df
$ git cat-file -p 384ec8c5f167e99bb47dfd3bbff7f5d23877c8df
100644 blob f213327331d92d4f91c2963cbb7c037eb3849555 README.md
100644 blob a4a10fd93d3b469fd68bbe63e14feefb33db101a second_file.txt
With git commit-tree we can create a commit object for our second commit.
$ echo "Second commit" | git commit-tree 384ec8c5f167e99bb47dfd3bbff7f5d23877c8df
7003976196bad64e70787237dafdd5c158f7d7d3
$ git cat-file -p 7003976196bad64e70787237dafdd5c158f7d7d3
tree 384ec8c5f167e99bb47dfd3bbff7f5d23877c8df
author Uncle Joe <[email protected]> 1697001383 +0000
committer Uncle Joe <[email protected]> 1697001383 +0000
Second commit
However, it doesn't have a parent commit. We have to specify one using the -p flag:
$ git commit-tree 384ec8c5f167e99bb47dfd3bbff7f5d23877c8df -p cd25c7d055e81836f43412ac8d5811d35319305a -m "Second commit"
34d5240a420fc4653a24f22d2f4fc11096712093
$ git cat-file -p 34d5240a420fc4653a24f22d2f4fc11096712093
tree 384ec8c5f167e99bb47dfd3bbff7f5d23877c8df
parent cd25c7d055e81836f43412ac8d5811d35319305a
author Uncle Joe <[email protected]> 1697001383 +0000
committer Uncle Joe <[email protected]> 1697001383 +0000
Second commit
I've kept the time between commits consistent, so every attribute remains the same. As you can see, the only difference now is that the commit has a parent. This alters the content of the commit and its SHA.
Now, you can checkout to the commit by updating the HEAD.
$ printf "34d5240a420fc4653a24f22d2f4fc11096712093" > .git/HEAD
$ git log --oneline
34d5240 (HEAD) Second commit
cd25c7d (main) Create README.md
Alternatively, you can update the HEAD to point to a branch that will point to the commit.
$ printf "34d5240a420fc4653a24f22d2f4fc11096712093" > .git/refs/heads/main
$ printf "ref: refs/heads/main" > .git/HEAD
$ git log --oneline
34d5240 (HEAD -> main) Second commit
cd25c7d Create README.md
A more user-friendly alternative to git commit-tree is git commit -m "Second commit". This porcelain command also updates the HEAD to point to the branch.
Rebase
Rebasing allows you to modify the commit history. Let's demonstrate this by first creating a new branch and adding two commits.
$ git checkout -b feature
$ echo "feature" > feature.txt
$ git add .; git commit -m "Add feature.txt"
$ echo "feature 2" > feature.txt
$ git add .; git commit -m "Add feature 2"
Next, switch to the main branch and add a new commit.
$ git checkout main
$ echo "main" > main.txt
$ git add .; git commit -m "Add main.txt"
$ git log --oneline --graph --all
* e0f4e4e (main) Add main.txt
| * 291a7ef (HEAD -> feature) Add feature 2
| * d72c441 Add feature.txt
|/
* 34d5240 Second commit
* cd25c7d Create README.md
After examining the history, rebase the feature branch onto the main branch and observe the history again.
$ git checkout feature
$ git rebase main
Successfully rebased and updated refs/heads/feature.
$ git log --oneline --graph --all
* 6f8dca0 (HEAD -> feature) Add feature 2
* 6f5b914 Add feature.txt
* e0f4e4e (main) Add main.txt
* 34d5240 Second commit
* cd25c7d Create README.md
Notice that the commits on the feature branch have different hashes. This is because Git rewrote each commit during the rebase. It created a new commit because tree sha is different, with added main.txt file. Also, the parent commit and date in the committer field have been changed.
$ git cat-file -p d72c441
tree a404b1d6f65c211409a79cdf723da7b490b694dc
parent 34d5240a420fc4653a24f22d2f4fc11096712093
author Uncle Joe <[email protected]> 1697754070 +0200
committer Uncle Joe <[email protected]> 1697754070 +0200
Add feature.txt
$ git cat-file -p 6f5b914
tree f09946e24f29857e3686c9497eb4a400ad63e347
parent e0f4e4e10bc112b9d9b63f1eda531473713a5813
author Uncle Joe <[email protected]> 1697754070 +0200
committer Uncle Joe <[email protected]> 1697754186 +0200
Add feature.txt
When merging the feature branch into main, Git might perform a fast-forward merge, meaning it won't create a new commit. Instead, it will move the main branch pointer to the new commit. This is because these two trees are the same.
$ git checkout -
Switched to branch 'main'
$ git merge feature
Updating e0f4e4e..6f8dca0
Fast-forward
feature.txt | 1 +
1 file changed, 1 insertion(+)
create mode 100644 feature.txt
$ git log --oneline --graph --all
* 6f8dca0 (HEAD -> main, feature) Add feature 2
* 6f5b914 Add feature.txt
* e0f4e4e Add main.txt
* 34d5240 Second commit
* cd25c7d Create README.md
Merge
Now, let's dive into the merging process. Let's start by creating a new branch and adding a commit to both branches:
$ git checkout -b feature2
$ echo "Make it cool" > feature2.txt
$ git add .; git commit -m "Make feature2.txt cool"
$ git checkout main
$ echo "Make it hot" > feature.txt
$ git commit -am "Make feature.txt hot"
$ git log --oneline --graph --all
* 09cc0e8 (feature2) Make feature2.txt cool
| * 0e6323f (HEAD -> main) Make feature.txt hot
|/
* 6f8dca0 (feature) Add feature 2
* 6f5b914 Add feature.txt
* e0f4e4e Add main.txt
* 34d5240 Second commit
* cd25c7d Create README.md
When merging feature2 into main, Git creates a new commit with two parents.
$ git merge feature2 --no-edit
Merge made by the 'ort' strategy.
feature2.txt | 1 +
1 file changed, 1 insertion(+)
create mode 100644 feature2.txt
$ git log --oneline --graph --all
* ceea4c9 (HEAD -> main) Merge branch 'feature2'
|\
| * 09cc0e8 (feature2) Make feature2.txt cool
* | 0e6323f Make feature.txt hot
|/
* 6f8dca0 (feature) Add feature 2
* 6f5b914 Add feature.txt
* e0f4e4e Add main.txt
* 34d5240 Second commit
* cd25c7d Create README.md
We can see that a new commit is created. If we inspect that commit it will show us not only its two parents, but also a different tree that does not belong to any of its parents. That's obvious for us now, but it shows that merge may have a different state of our source.
$ git cat-file -p ceea4c9
tree d1c55d17ca12c3f0a07525b594d36c079e856f1a
parent 0e6323f4a77ce839323d500b82bdd7cc36876ca6
parent 09cc0e8a6fafa6369e1a2e73d8c5deb928d53848
author Uncle Joe <[email protected]> 1697755302 +0200
committer Uncle Joe <[email protected]> 1697755302 +0200
Merge branch 'feature2
$ git cat-file -p 0e6323f4a77ce839323d500b82bdd7cc36876ca6
tree 407f5a52fe6cc0db7fc29d4db5301916599de0b8
...
$ git cat-file -p 09cc0e8a6fafa6369e1a2e73d8c5deb928d53848
tree 14461ef613d6d47bb244107541416256784e60eb
...
That's especially true, if we have a conflict.
$ git checkout -B feature2
$ echo "Make it cool again" > feature2.txt
$ git commit -am "Make feature2.txt cool again"
$ git checkout main
$ echo "Make it hot now" > feature2.txt
$ git commit -am "Make feature2.txt hot now"
$ git log --oneline --graph --all
* 29e7c5f (feature2) Make feature2.txt cool again
| * b44946b (HEAD -> main) Make feature2.txt hot now
|/
* ceea4c9 Merge branch 'feature2'
Now if we merge feature2 to main, the git client will let us know about the conflict. Once we've resolved it, a new commit with two parents will be created, showcasing the resolved version of the file.
$ git merge feature2
Auto-merging feature2.txt
CONFLICT (content): Merge conflict in feature2.txt
Automatic merge failed; fix conflicts and then commit the result.
$ cat feature2.txt
<<<<<<< HEAD
Make it hot now
=======
Make it cool again
>>>>>>> feature2
$ echo "Keep it cool" > feature2.txt
$ git add feature2.txt
$ git merge --continue --no-edit
[main f843141] Merge branch 'feature2'
$ git log --oneline --graph --all
* f843141 (HEAD -> main) Merge branch 'feature2'
|\
| * 29e7c5f (feature2) Make feature2.txt cool again
* | b44946b Make feature2.txt hot now
|/
* ceea4c9 Merge branch 'feature2'
Given the above examples with both conflict, non-conflict and fast-forward merge scenarios, can you determine the differences in the commit trees?
In conclusion, we compared recursive and fast-forward merge. It's also vital to understand that rebase isn't a merge but a rewriting of history. I recommend rebasing your branch onto the main branch before merging. This not only results in a cleaner commit history but also simplifies code testing. If two branches share the same commit hash, you can be certain they have identical codebases.
Aliases
In Git, branches are pointers to specific commits, and the list of branches is stored in the .git/refs/heads directory. To create your own branch, you can simply create a file with the name of your branch and place the hash of the sha of the commit you want to point to within that file.
If we want, we can take a look at the directory containing branch references. For instance, examining the contents of the feature2 branch file.
$ ls .git/refs/heads
feature feature2 main
$ cat .git/refs/heads/feature2
29e7c5f1f34706803b7e30d5eaf0ce8dfa1d2e4c
Git also includes a special file called HEAD, which we looked at earlier.
In addition to managing branches, Git provides built-in aliases for convenience:
HEAD~2refers to the two commits above the current position.branch_name^refers to the parent commit of a branch.branch_name~2refers to a commit two steps above a branch.
You can utilize these aliases with various Git commands. For example, to edit the history of the last three commits, you can use git rebase -i HEAD~3.
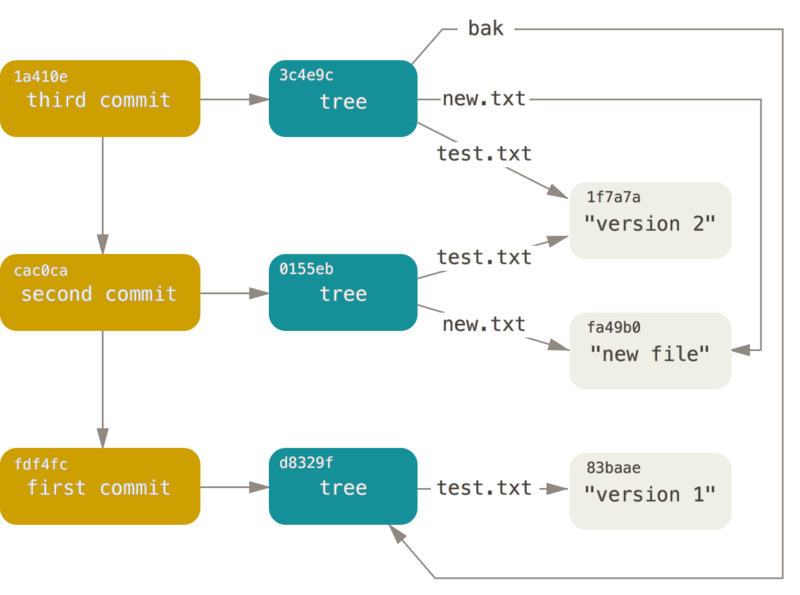
Aside from branches, Git also offers the concept of tags (git tag) that function similarly but are typically associated with specific commits. Notably, there is a distinction between regular and annotated tags. Annotated tags have their object type and point to a commit. They also store information about who created the tag and when.
$ git tag v1
$ cat .git/refs/tags/v1
f8431410c33fbabe0a4f139af61e6f280e9f8b1c
$ git cat-file -t f8431410c33fbabe0a4f139af61e6f280e9f8b1c
commit
$ git tag -a v2 -m "Version 2"
$ cat .git/refs/tags/v2
12705094e6c5b2e879899799cbc9146c22a4105a
$ git cat-file -t 12705094e6c5b2e879899799cbc9146c22a4105a
tag
$ git cat-file -p 12705094e6c5b2e879899799cbc9146c22a4105a
object f8431410c33fbabe0a4f139af61e6f280e9f8b1c
type commit
tag v2
tagger Uncle Joe <[email protected]> 1697757110 +0200
Version 2
Now, you know that if you have a branch or tag production and it points to the same commit on branch staging. You are 100% sure that you have the same version of the service codebase in both environments. If this is important to you, you know how you can get that.
Saving Space
In this section, we'll delve into how Git conserves space through its garbage collection process (git gc). Periodically, Git executes this command to remove objects that are no longer referenced by any branch or tag, as well as to compact all objects into a single file. This process significantly reduces storage space requirements. The last part is a bit more advanced. Let's examine how Git accomplishes this:
$ git count-objects -H
50 objects, 200.00 KiB
$ git gc # Git garbage collector
Enumerating objects: 44, done.
Counting objects: 100% (44/44), done.
Delta compression using up to 8 threads
Compressing objects: 100% (33/33), done.
Writing objects: 100% (44/44), done.
Total 44 (delta 19), reused 0 (delta 0), pack-reused 0
Enumerating cruft objects: 6, done.
Traversing cruft objects: 11, done.
Counting objects: 100% (6/6), done.
Delta compression using up to 8 threads
Compressing objects: 100% (6/6), done.
Writing objects: 100% (6/6), done.
Total 6 (delta 2), reused 0 (delta 0), pack-reused 0
$ git count-objects -H
0 objects, 0 bytes
Upon running git gc, you'll notice that Git has removed unreferenced objects, resulting in a significant reduction in storage. However, the objects are not deleted but rather compacted into a pack file. Let's take a look at the contents of the .git/objects directory:
$ tree -C .git/objects
.git/objects
├── info
│ ├── commit-graph
│ └── packs
└── pack
├── pack-55bba4df36ff08e389e6cd9614c7d6cbc423c2f2.idx
├── pack-55bba4df36ff08e389e6cd9614c7d6cbc423c2f2.mtimes
├── pack-55bba4df36ff08e389e6cd9614c7d6cbc423c2f2.pack
├── pack-55bba4df36ff08e389e6cd9614c7d6cbc423c2f2.rev
├── pack-7a7ad1682d2a0b4322bf87bee27651168b555355.idx
├── pack-7a7ad1682d2a0b4322bf87bee27651168b555355.pack
└── pack-7a7ad1682d2a0b4322bf87bee27651168b555355.rev
Git has moved these object files into pack files. Let's explore the contents of one such pack file:
$ git verify-pack -v .git/objects/pack/pack-55bba4df36ff08e389e6cd9614c7d6cbc423c2f2.idx
4e228d1684edd5095207a39836c7dab7c191d2ca commit 232 156 12
1787a887178854b75a4d1bfd139dd4f71a7510fd commit 42 53 168 1 4e228d1684edd5095207a39836c7dab7c191d2ca
7003976196bad64e70787237dafdd5c158f7d7d3 commit 168 121 221
68c568bdb990d310b1d6a7e45abe8cc36dac75ae commit 6 16 342 1 7003976196bad64e70787237dafdd5c158f7d7d3
a670bc001f27602bc60c7c1cb7b3e807de3413c1 blob 73 63 358
d86637cf7327681b0fb1078458bf8986976f89a6 tree 195 174 421
non delta: 4 objects
chain length = 1: 2 objects
.git/objects/pack/pack-55bba4df36ff08e389e6cd9614c7d6cbc423c2f2.pack: ok
For objects that haven't been deltified in the pack file, the output format is:
SHA-1 type size size-in-packfile offset-in-packfile
For deltified objects, the format includes additional information:
SHA-1 type size size-in-packfile offset-in-packfile depth base-SHA-1
The example below demonstrates space savings, especially when dealing with larger files. Git identifies files with similar names and sizes and stores only the differences between versions, resulting in reduced storage requirements. For instance:
$ ruby -r securerandom -e '1000.times { puts SecureRandom.hex(1000) } ' > big_file.txt
$ ls -lh big_file.txt
-rw-r--r-- 1 user staff 1.9M Oct 20 01:29 big_file.txt
$ git add big_file.txt; gc -m "Create big_file.txt"
$ ruby -r securerandom -e '5.times { puts SecureRandom.hex(1000) } ' >> big_file.txt
$ gc -am "Make big_file.txt a little bigger"
After running git gc, you'll notice that the second commit's file (7eb03) size has been significantly reduced from ~2MB to 1.1MB. The file from the first commit (097eca) now uses it and occupies only 78 bytes of disk space. This space-saving mechanism relies on Git detecting files with similar names and sizes and storing only the deltas between versions in pack files.
$ git gc
$ git verify-pack -v .git/objects/pack/pack-5549d115aee92a928cf6814c0cbd7858256e1dea.idx
...
7eb03b8ab7370fe22729d67bbf1ae0e0ac4620c3 blob 2011005 1146572 3289
097eca0b36ca97da272913cd96785c289d856d5e blob 69 78 1149861 1 7eb03b8ab7370fe22729d67bbf1ae0e0ac4620c3
...
Git Server on Disk
Now that we have manually created our first Git repository, the next question is how to share it with others? While you can use the git daemon command to run a server that serves your repository, there is a simpler method that mimics the GitHub experience.
To create a repository server, you can start by creating a bare repository using the following command:
$ git clone --bare my-project my-project.git
This essentially creates a minimal version of the .git directory. One that doesn't contain a working directory.
From this point forward, you can use this directory as a remote repository for your local computer:
$ git clone path/to/my-project.git
If you wish to upload this directory to your server, for example, git.airhelp.com, you can do so. It will function in a similar way to the created one on GitHub or GitLab:
$ scp -r my-project.git [email protected]:/srv/git
At this stage, any user who has SSH-based read access to the /srv/git directory on your server can clone your repository by running:
$ git clone [email protected]:/srv/git/my-project.git
Furthermore, if a user has write access to the /srv/git/my-project.git directory, they will also automatically have push access.
This approach allows you to create your own self-hosted remote repository, making your version control process fully decentralized.
Questions for you
To sum up your knowledge, I have some questions for you:
- When modifying a git object, when does the git client throw an error, and when doesn't it?
- How would you verify data integrity if the commit SHA is different?
- How does forking work?
- Why does the merge commit not have the same SHA if its tree is common with one of its parents?
Thank you for reading. I hope you learned something new. If you have any questions, feel free to contact me. I look forward to seeing you in the next article.
Further reading
- I recommend checking out these animations to visualize how some porcelain commands work: https://dev.to/lydiahallie/cs-visualized-useful-git-commands-37p1
- Videos:
- Google Tech Talk: Linus Torvalds on the Git mindset - https://www.youtube.com/watch?v=4XpnKHJAok8
- If you want to recap your knowledge, I recommend watching Emily Xie's talk: https://www.youtube.com/watch?v=Y2Msq90ZknI
- Next, watch Matthew McCullough (Github VP) dive deeper into the subject: https://www.youtube.com/watch?v=ig5E8CcdM9g
- To read more about git internals, I recommend the following manual and book written by GitHub co-founders Scott Chacon and Ben Straub:
- Git Internal Objects - https://git-scm.com/book/en/v2/Git-Internals-Git-Objects
- Setting Up Your Servers - https://git-scm.com/book/en/v2/Git-on-the-Server-The-Protocols
- Git Daemon - https://git-scm.com/book/en/v2/Git-on-the-Server-Git-Daemon
- Git Plumbing and Porcelain - https://git-scm.com/book/en/v2/Git-Internals-Plumbing-and-Porcelain
- Index (Stash) - https://git-scm.com/docs/index-format
- Pack - https://git-scm.com/docs/pack-format
- StackOverflow answer about how the index works - https://stackoverflow.com/a/4086986
- Git Flows:
- My personal favorite: The simple GitHub flow - https://docs.github.com/en/get-started/quickstart/github-flow
- While considered obsolete for modern web development, it's still worth reading: https://nvie.com/posts/a-successful-git-branching-model/
- Somewhere in between: The GitLab flow - https://about.gitlab.com/topics/version-control/what-are-gitlab-flow-best-practices/

Paweł Bajorek
Senior Software Engineer