Lessons from Development and Roll-out of Backend for a Mobile App
Building the backend for a mobile app is a unique challenge, full of small surprises and big decisions. This post is based on my experience as the backend developer for AirHelp's new mobile app. Over many months, I worked closely with our mobile and product teams to design, build, and launch the Mobile App Gateway, a key system that connects the app with our internal services.
Here, I want to share my main lessons from this journey. I'll cover topics like handling anonymous sessions, monitoring, error handling, scaling, and more. These are real observations from building and running a product in production. If you're working on a mobile app backend, I hope these tips help you avoid some common problems.
1. Handling Anonymous Sessions and Device Installations
A big lesson from building AirHelp's mobile backend was adapting to the requirement that anonymous users should be able to use our systems: search for flights, create trips, and receive notifications, all without signing up.
To support this, we had to introduce a brand new concept: the anonymous user. Now, every time a user installs the app, we create an anonymous user profile and a unique installation ID. This lets us identify and track anonymous sessions for each device.
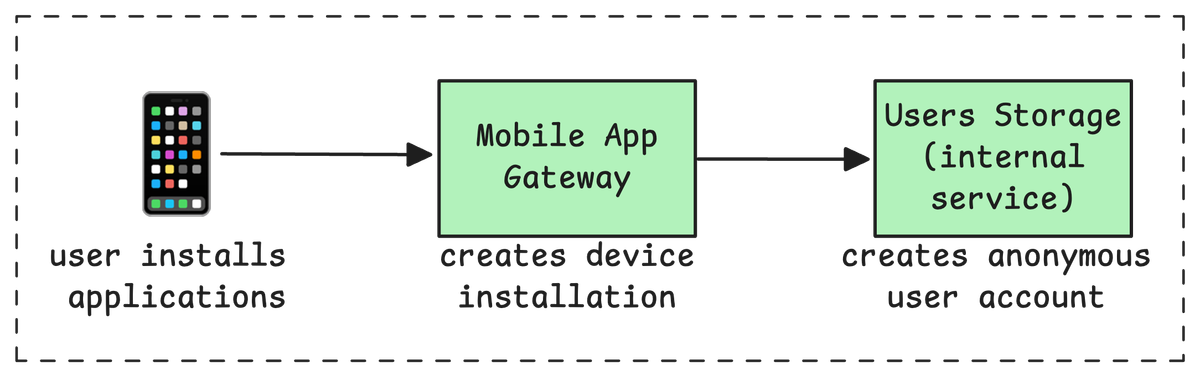
The technical solution was simple but important: treat anonymous users as real users in our backend. This meant proper session creation, tracking data and actions, and handling notifications, just like for registered users. If you want anonymous use in your app, you need to design for it from day one, your backend has to recognize and remember these users properly.
2. One Installation, Many Scenarios
Mobile apps live on physical devices, and every device brings its own reality. Users may switch phones, use more than one device, share a tablet with a family member, or reinstall your app. Each of these events can affect how sessions, data, and push notifications are handled.
To keep things organized in our backend and avoid database chaos, every device installation is always identified by a pair (installation_id, user_id). This means that for each installation, we know exactly which user is active, whether it's an anonymous session or a logged-in account.
When a user signs up or logs in, we link their anonymous session to the new account and retain their data (like trips or preferences). This lets users continue seamlessly after authentication, without data loss or duplicate profiles.
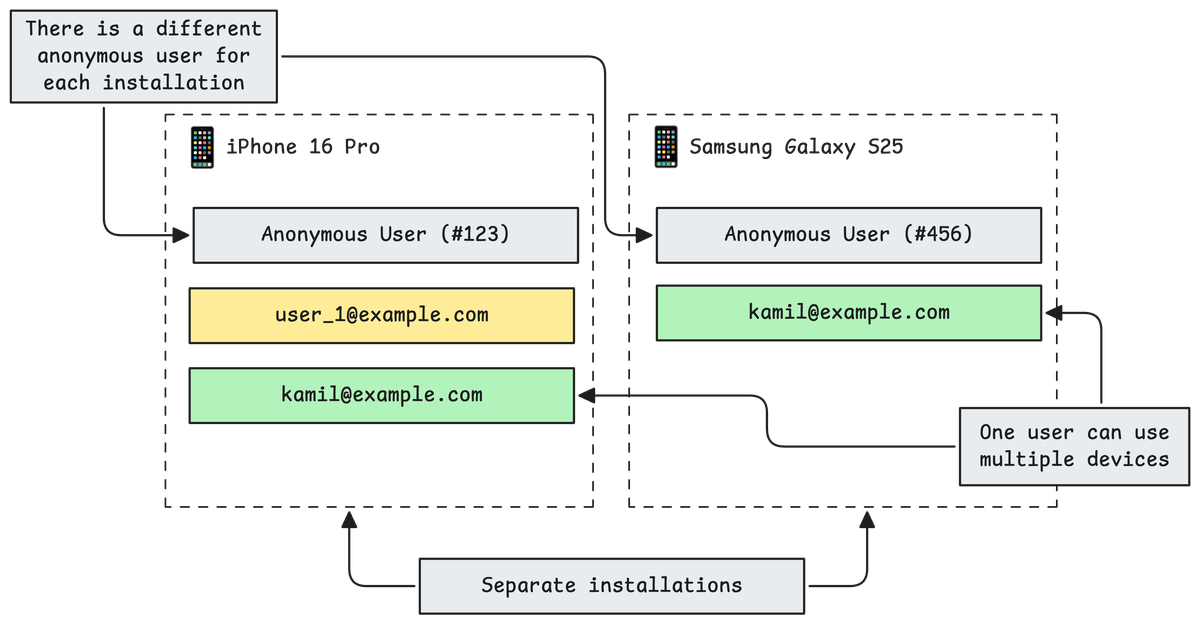
For every installation, we also guarantee there is exactly one anonymous user installation. When someone installs the app on a device for the first time, an anonymous installation and user profile are always created. The installation_id is stored securely on the device (for example, in the iOS keychain or Android keystore). Because of this, even if the app is uninstalled and reinstalled, we can reuse the same installation_id and tie everything back to the correct anonymous user profile.
This setup gives us several important wins:
- We can support multiple devices per user and safely route data and notifications.
- If two (or more) users share a device, each can log in, log out, and see only their own data.
- We avoid database clutter, since installations are always tracked by their (installation_id, user_id) pair, and every device always has a single anonymous profile to return to.
Trying to build a single-user, single-device system for mobile is a trap, real usage is always more messy. Handle every installation as its own identity, and always be ready to manage multiple devices per user, or multiple users per device.
3. Monitoring What Matters
When it comes to running a backend for a mobile app, monitoring is much more than just checking if your servers are "up". Careful tracking of what's going wrong, especially 4XX errors, is just as important as counting success.
4XX errors (client-side issues) can tell you a lot about how real users are exploring your app. Sometimes, these errors don't mean something is broken on your side, they mean people are trying new or unexpected usage flows. For example, after launch, we saw a surprising number of 404 "Not Found" errors. It turned out users were trying to monitor flights too far in advance, before we had any tracking info. Without these error metrics, we would have missed this real customer need.
At the same time, monitoring 5XX errors (server-side issues) and timeouts is non-negotiable. These are true indicators that your backend isn't coping, there's a bug, or a third-party service is down. We tracked every spike and set up alerts, so we could fix problems fast, often before users even had a chance to complain. Timeout rates, especially on key endpoints like push notifications or trip creation, were excellent early warnings of bugs or scaling trouble.
Besides errors, business metrics were key to understanding our rollout. We monitored the number of installations per platform and per app version, tracked activation rates, and checked which devices were the most active. On the technical side, we watched HTTP traffic, measured resource usage, and checked how much autoscaling was happening.
The big lesson here: good monitoring should cover both technical health and real user actions. Don't just watch server graphs, track what your users are really doing, what flows they're triggering (even broken ones), and how your business metrics are changing day by day.
4. Seeing the Whole Request Journey
Most requests from the app go through several microservices. Debugging problems meant we needed to see the full path of a request. Distributed tracing was essential, it let us follow each request end-to-end and quickly find where things broke.
Error tracking tools like Sentry helped us group and fix bugs faster, especially after new releases. This gave us much faster feedback when a new version introduced a bug, or when certain flows caused unexpected crashes only in production.
One real example: We once noticed payment errors coming from Stripe, caused by missing user emails. Using distributed tracing, we were able to quickly track down all requests from the affected user, even though it was an anonymous profile with no personal details. By linking the user's installation ID and tracing their request path, we confirmed that an anonymous user was somehow able to trigger a payment flow, which should not have been possible. This helped us spot a missing validation and fix the bug before it could affect production users. Without end-to-end tracing, finding the root cause would have taken much longer, since the error didn’t include any obvious user data.
5. Preventing Cascading Failures
In backend systems, especially those using microservices, circuit breakers are your first line of defense against cascading failures. But knowing where and how to use them is just as important as using them at all.
Early on, we realized that a single internal service might power multiple features in the app. For example, one endpoint might provide flight status, while another returns historical trips, all handled by the same upstream microservice. If one feature suddenly became unavailable, it didn't mean that every feature from that service was down.
That's why we decided to implement circuit breakers per feature (endpoint), not just per service. This allowed us to quickly "close" the circuit for a specific failing route, while still letting healthy endpoints in the same service continue working. If the flight status endpoint started timing out, users could still search for other information or create new trips without disruption.
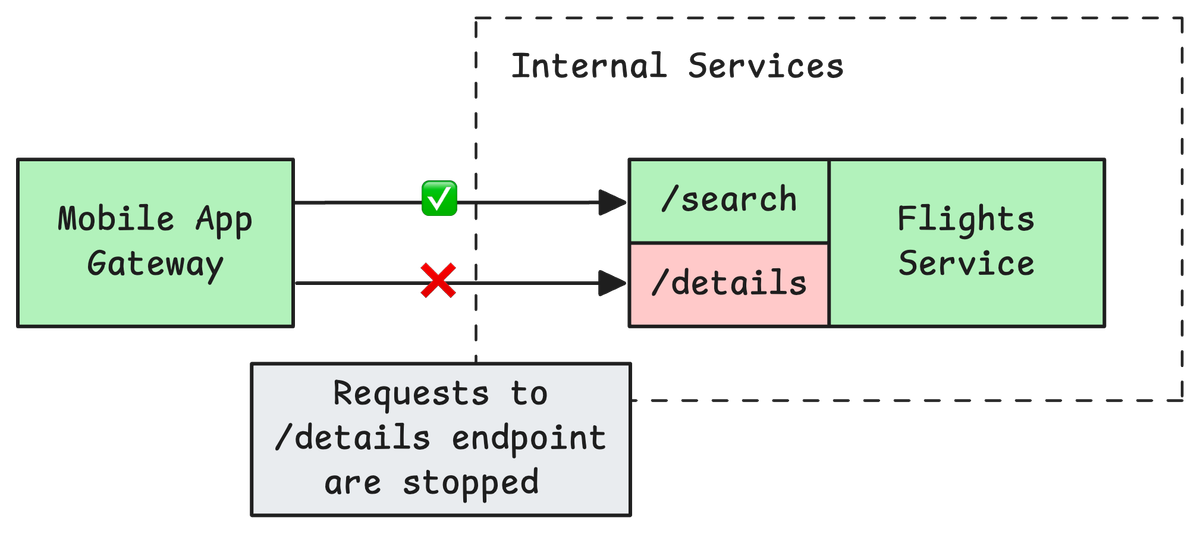
If you care about user experience (and uptime), a feature-level circuit breaker is a must. It keeps partial outages from spreading and gives users a much better chance of falling back gracefully.
6. Planning for Real-World Change a.k.a API Versioning
If there's one lesson every backend developer learns the hard way, it's this: your APIs will need to change, and old mobile clients will always stick around longer than you hope.
We chose a straightforward approach: prefixing every route with the API version, like /api/v1/ or /api/v2/. This makes it clear which version the app is using and lets us evolve the API safely, without breaking older clients overnight.
At the same time, we adopted a sensible rule for changes: additive updates, such as adding new fields to a response, don't break the contract for existing clients. Our mobile app simply ignores unknown fields if it isn't expecting them. This means we can introduce new features fast, without having to cut a new version for every small change.
Only when we need to make breaking changes (like removing or renaming a field, or changing behavior in a way that older apps can't handle) do we publish a new, separate API version. This keeps support simple and the migration path clear for the mobile team
7. Scaling for Growth
One of the most practical lessons from launching a mobile backend is that traffic patterns are rarely steady. Especially around major releases or ad campaigns. User surges can be unpredictable, and the cost of downtime is high.
To keep our systems responsive and resilient, we set up autoscaling based on the number of active NGINX connections to each Mobile Gateway pod. Our configuration kept a minimum of 4 pods running at all times, scaling up to 10 pods as needed, with a 1-minute cooldown period to avoid thrashing during sudden spikes.
But autoscaling alone isn't enough. For launch day and marketing pushes, we deliberately overprovisioned both the Mobile Gateway and upstream services. This meant allocating extra resources in advance, even if it seemed wasteful in the short term, to ensure we could absorb sudden bursts of traffic without slowdowns or errors.
To further protect the system, we added a CloudFlare rate limiter in front of our public endpoints. This gave us an extra layer of defense against abusive traffic and bot storms, and helped smooth out load peaks before they hit our backend.
8. Handling Failures, Support Collaboration, and Upholding SLAs
Failures are part of running any backend. We set up fast alerts for critical errors and made sure both engineers and support teams could respond quickly. For potential SLA impacts, we used a shared channel for real-time updates between backend, mobile, and support teams.
We followed a clear incident response process: define the problem, communicate plans, track SLAs, and review incidents to improve. This built trust with our users and support team.
Conclusions
Building a mobile app backend is about much more than code. Real users, real devices, and real-world surprises will test your system. The most important lessons are to design for flexibility, monitor what matters, communicate openly, and treat every incident as a way to improve.
If you have questions or want to share your own experiences, feel free to reach out. I'm always happy to discuss backend design!

Kamil Woźniak
Senior Software Engineer, Tech Lead