WAL overgrowth protection

The Hidden Risk That Can Bring Down Your Production Database
PostgreSQL replicas are designed to enhance system reliability and performance, but they can paradoxically become a threat to your master database's stability. When replicas fail to keep up with Write-Ahead Log (WAL) consumption, they can trigger a cascade of issues that ultimately lead to production outages.
This article explores how WAL accumulation can crash your master database and demonstrates how PostgreSQL's max_slot_wal_keep_size parameter provides essential protection against this scenario.
Understanding the Problem: Storage Depletion
The most critical issue occurs when replicas cannot keep pace with WAL log consumption (or WAL log consumers become unavailable). In this scenario, WAL logs accumulate on the master node, progressively consuming available storage until the database becomes unavailable.
The Core Problem: WAL Accumulation
PostgreSQL maintains Write-Ahead Logs for replicas to ensure data consistency and durability. However, when replicas become unavailable or fall behind, the master continues to retain WAL files that haven't been acknowledged. This protective mechanism becomes problematic when:
- Undersized replicas cannot process WAL logs at the required rate
- Network connectivity issues prevent replica communication
- Logical replication consumers (such as ETL tools like Fivetran) are paused or fail
PostgreSQL's Built-in Safety Net: max_slot_wal_keep_size
PostgreSQL 13 introduced a crucial protection mechanism through the max_slot_wal_keep_size parameter:
-- Configure in your RDS Parameter Group
max_slot_wal_keep_size = 10000 -- 10GB limit
-- Default value is "-1" (no limit)
This parameter automatically invalidates replication slots when WAL accumulation exceeds the specified limit, protecting the master database from disk exhaustion while stopping replication to problematic consumers.
Proof of Concept: Testing WAL Protection Mechanisms
To validate the effectiveness of max_slot_wal_keep_size in protecting our master database, we conducted a controlled experiment to observe its behavior under realistic failure conditions.
Test Environment Setup
Our test environment consisted of:
- Master Database: AWS RDS PostgreSQL instance with ~40.52 GB free storage
- Physical Replica: AWS RDS read replica with ~40.52 GB free storage
- Logical Replication Consumer: External SaaS application utilizing a logical replication slot
Methodology
The experiment followed these steps:
- Configure
max_slot_wal_keep_size = 10GBon both master and replica - Pause WAL processing on the SaaS application to simulate a stuck consumer
- Allow WAL logs to accumulate naturally under normal database operations
- Monitor system behavior and automatic recovery mechanisms
Test Results
The logical replication slot was automatically invalidated when WAL accumulation exceeded the configured limit of 10,240 MB (10 GB), demonstrating the parameter's effectiveness in protecting the master and replica databases.
Without this safety mechanism, free storage space on the replica would continue to decrease as WAL files accumulate, making it fail, and free storage on the master would eventually be exhausted, leading to complete database failure. We experienced this exact scenario in our testing environment, where an unresponsive replica caused WAL accumulation that eventually crashed both the replica and its master database.
The following chart illustrates WAL size and free storage space throughout the 14-hour test period, showing the complete cycle of WAL accumulation, critical limit breach, and automatic recovery:
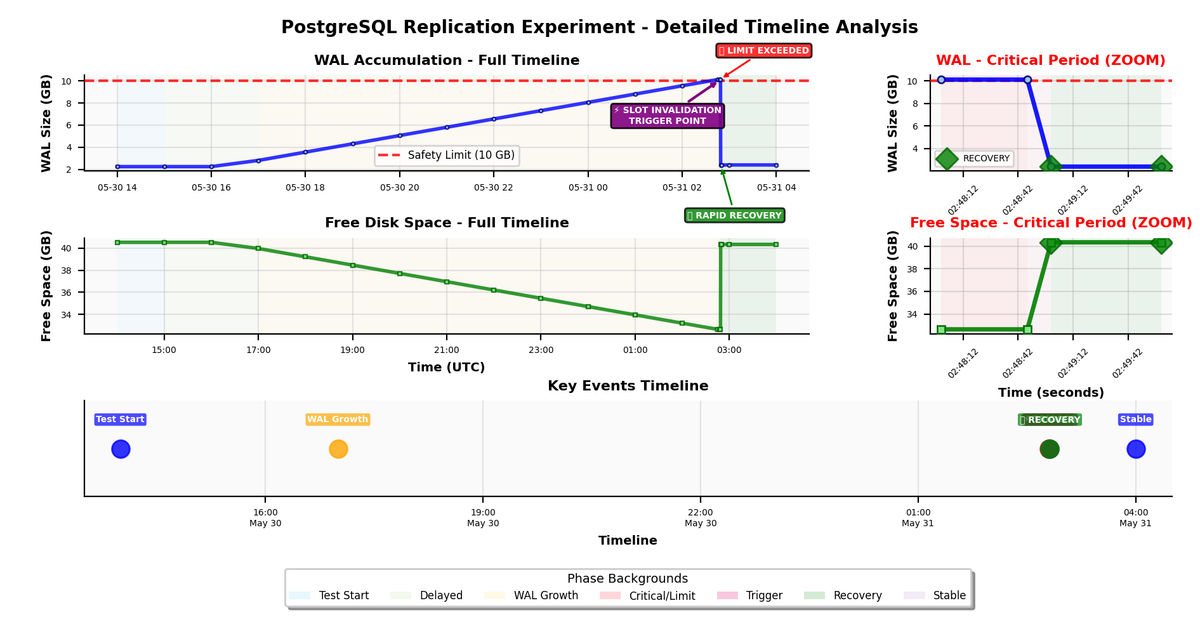
Detailed Timeline Analysis
Phase 1: Initial Stability (14:00 - 16:00)
- Duration: 2 hours
- WAL Size: Stable at 2.25 GB
- Free Storage: Stable at 40.52 GB
- Status: Normal operation with no observable disk impact
Phase 2: WAL Accumulation Period (17:00 - 02:45)
- Duration: 9 hours 45 minutes
- WAL Growth: Linear increase from 2.81 GB to 10.12 GB
- Storage Impact: Free space decreased from 39.96 GB to 32.65 GB
- Status: Progressive escalation from normal operation to near-limit conditions
Phase 3: Critical Event (02:48)
- Trigger: Maximum WAL limit exceeded (10.12 GB)
- System Response: Replication slot protection mechanism activated
- Outcome: Automatic slot invalidation and immediate recovery initiation

Phase 4: Recovery and Stabilization (02:49 - 04:00)
- Recovery Time: Less than 1 minute
- WAL Reduction: From 10.12 GB to 2.4 GB (76% reduction)
- Storage Recovery: Free space restored from 32.65 GB to 40.33 GB
- Result: Complete return to normal operation within 1 minute
Key Takeaways and Best Practices
Our testing demonstrates that max_slot_wal_keep_size provides reliable protection against WAL-induced storage exhaustion. The parameter successfully prevented master database failure by automatically invalidating problematic replication slots when WAL accumulation reached critical levels.
Implementation Recommendations
- Configure WAL limits: Set
max_slot_wal_keep_sizeto an appropriate value based on your storage capacity and business requirements - Monitor storage metrics: Implement alerting on
FreeStorageSpaceto detect accumulation trends before they become critical - Test your configuration: Validate protection mechanisms in non-production environments to ensure they work as expected
- Plan for consumer failures: Design your replication consumers with automatic restart capabilities and proper error handling
Conclusion
Replication safety is not optional - it's critical infrastructure protection. While replicas are designed to enhance system reliability, they can become single points of failure if not properly configured and monitored.
Remember: Your replica's problems inevitably become your master's problems.
By implementing proper WAL protection mechanisms and monitoring, you can ensure that replication enhances rather than threatens your database infrastructure's stability.

Michał Łasisz
DevOPS Engineer